|
Below is some text I wrote outlining the technical infrastructure for
at thing we colloquially call the "catholic
portal" (www.catholicresearch.net). Does the infrastructure make
sense to y'all? If it doesn't make sense to you, then it won't make
sense to non-technoweenies.
Catholic Research Resources Initiative and its technical infrastructure
This text outlines the proposed technical infrastructure for the
Catholic Research Resources Initiative (CRRI).
The infrastructure begins with two assumptions. First, from the
user's point of view, the system provides a searchable/browsable
interface to sets of EAD (Encoded Archival Document) files. Second,
the system makes every effort to provide this interface through well-
established Web-based protocols thus making the underlying components
more modular.
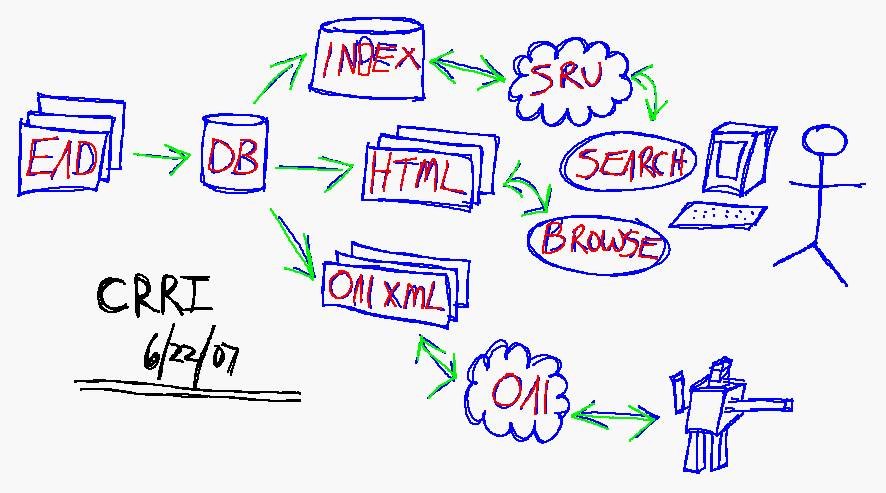
Figure 1 illustrates the proposal. Starting on the far left are sets
of EAD files. These files will be created remotely at partner
institutions and sent to a central location. Once received metadata
will be extracted and stored in a relational database along with the
entire EAD files. This metadata, in combination with a simple faceted
classification system, will provide a way to maintain and logically
organize the CRRI content. We propose to use MySQL as the relational
database and a set of object-oriented Perl modules called MyLibrary
to facilitate input/output against the database. [1, 2]
To facilitate search, a report will be written against the database
and given to an indexing program. The indexer/search engine is
expected to support fielded, free-text, and full-text searching, as
well as relevancy ranking. More importantly, the search engine is
expected to be accessible through a Web Services-based protocol
called SRU (Search-Retrieve via URL). [3] This will enable other
information services to search the CRRI without using the CRRI
website. Examples of other information services include metasearch
interfaces now common in libraries. The use of SRU will also enable
the CRRI to exchange its underlying indexing program without changing
the user interface. We plan to use either Zebra, Kinosearch, or
Lucene as our indexing program. [4, 5, 6]
To facilitate browse the increasingly popular "faceted navigation"
technique will be employed. Using the metadata contained in the EAD
files, very broad "facets" will be created. Examples include
subjects, formats, people, institutions, themes, and maybe dates.
Each facet will have associated with it sets of "terms" such as
African Americans, letters, Dorothy Day, Seton Hall University, or
Catholic Social Action. Through a second set of reports, these facet/
term combinations will be displayed in a user's browser, and by
selecting them relevant content will be returned.
To broaden access to the CRRI's content, a third set of reports will
be written against the database to enable OAI-PMH (Open Archives
Initiative - Protocol for Metadata Harvesting). [7] These reports
will result in the creation of sets of XML files saved to the
computer's file system. An OAI "data repository" application will
provide access to the files and enable OAI "service providers" to
read the metadata and use it in other applications. We plan to use
XMLFile for the data repository. [8] An example of a service provider
is OAIster. [9]
Links
1. MySQL - http://mysql.com
2. MyLibrary - http://dewey.library.nd.edu/mylibrary
3. SRU - http://loc.gov/standards/sru
4. Zebra - http://indexdata.dk/zebra
5. Kinosearch - http://rectangular.com/kinosearch
6. Lucene - http://lucene.apache.org
7. OAI-PMH - http://openarchives.org
8. XMLFile - http://www.dlib.vt.edu/projects/OAI/software/xmlfile
9. OAIster - http://oaister.org
--
Eric Lease Morgan
University Libraries of Notre Dame
|













{kind=link}