Hi Jean,
> So, I was wondering if any one had an example Python or Perl script for
> reading RDF/XML, Turtle, or N-triples file. A simple/partial example
> would be fine.
I worked on a Perl script for reading RDF during last year's OCLC Developer House event.
I used the Perl "RDF::Helper" module since it claimed to "Provide a consistent, high-level API for working with RDF with Perl" [1]. There was a bit of a learning curve and I was not able to find much in the way of RDF::Helper code examples on the interwebs.
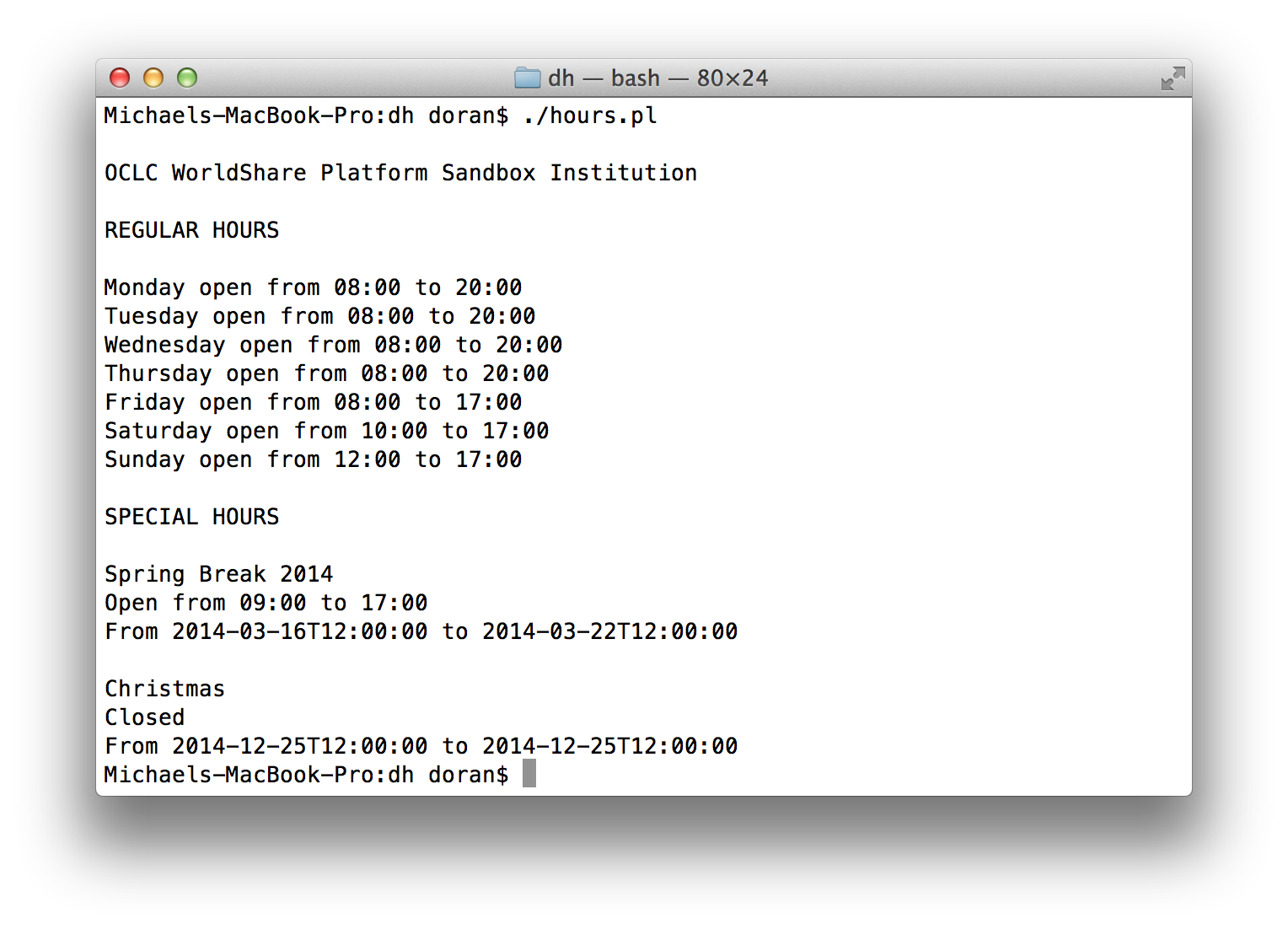
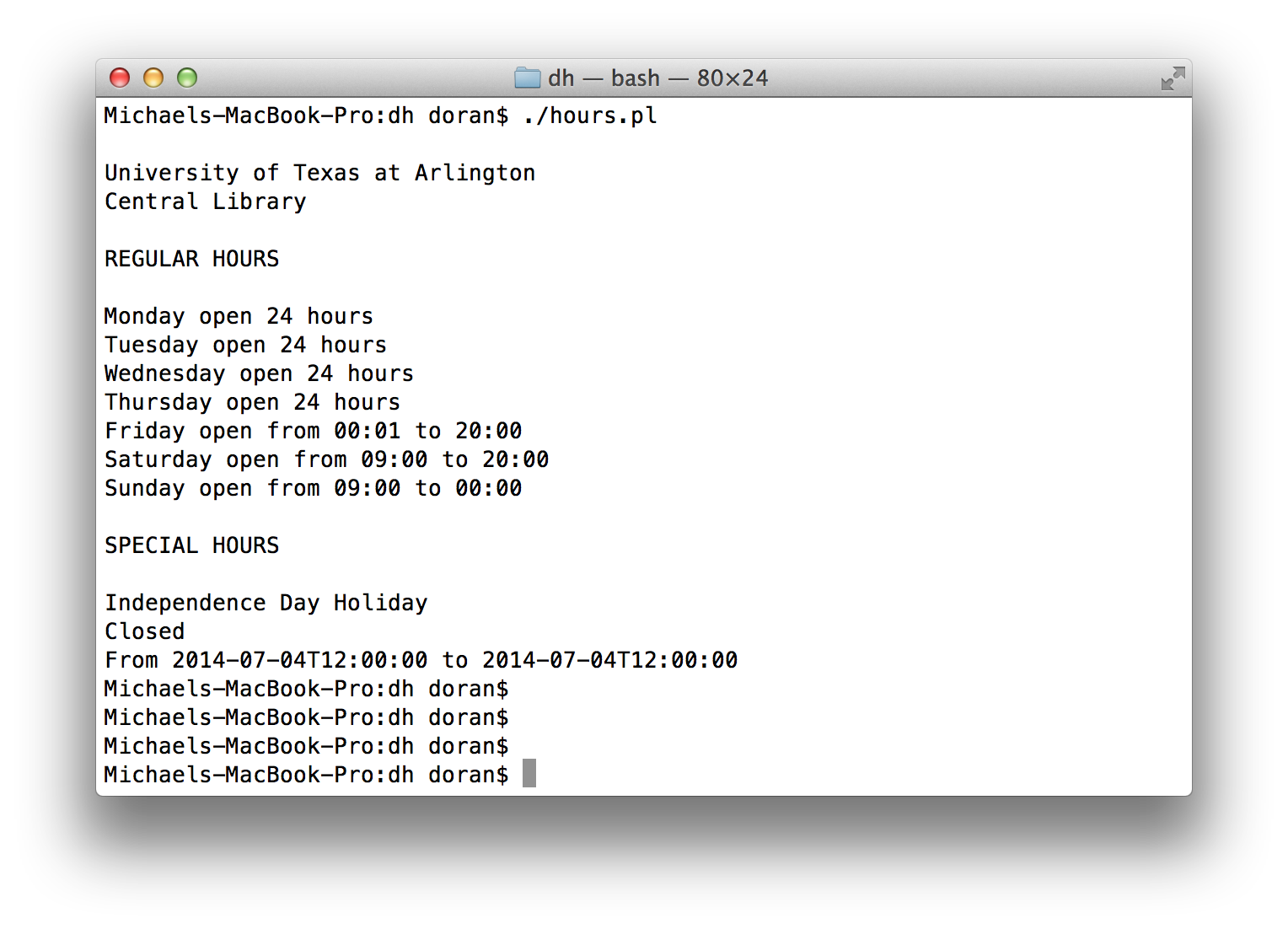
For the OCLC Developer House project, we were extracting, parsing, and displaying a library's hours from institutional data in the OCLC WorldCat Registry [2]. I've attached a perl "proof-of-concept" script and a couple of screen shots showing output. The script file has an additional ".txt" file extension for safe travels thru email. The script requires non-core perl module(s), as well as specifying a path to a CA Root certs file (for HTTPS gets).
The other Developer House "Registry Hours" project team members worked on a PHP script to do essentially the same thing (although more elegantly and with more functionality). Their code is available on Github [3].
Good luck!
- Michael Doran
[1] http://search.cpan.org/dist/RDF-Helper/
[2] Examples of data for UTA Libraries:
https://worldcat.org/wcr/normal-hours/data/2928
https://worldcat.org/wcr/special-hours/data/2928
[3] https://github.com/oclc-developer-house/wclibhours
# Michael Doran, Systems Librarian
# University of Texas at Arlington
# 817-272-5326 office
# 817-688-1926 mobile
# [log in to unmask]
# http://rocky.uta.edu/doran/
> -----Original Message-----
> From: Code for Libraries [mailto:[log in to unmask]] On Behalf Of
> Jean Roth
> Sent: Tuesday, September 30, 2014 9:14 AM
> To: [log in to unmask]
> Subject: [CODE4LIB] Python or Perl script for reading RDF/XML, Turtle, or
> N-triples Files
>
> Thank you so much for the reply.
>
> I have not investigated the LCNAF data set thoroughly. However, my
> default/ideal is to read in all variables from a dataset.
>
> So, I was wondering if any one had an example Python or Perl script for
> reading RDF/XML, Turtle, or N-triples file. A simple/partial example
> would be fine.
>
> Thanks,
>
> Jean
>
> On Mon, 29 Sep 2014, Kyle Banerjee wrote:
>
> KB> The best way to handle them depends on what you want to do. You need
> to
> KB> actually download the NAF files rather than countries or other small
> files
> KB> as different kinds of data will be organized differently. Just don't
> try to
> KB> read multigigabyte files in a text editor :)
> KB>
> KB> If you start with one of the giant XML files, the first thing you'll
> KB> probably want to do is extract just the elements that are interesting
> to
> KB> you. A short string parsing or SAX routine in your language of choice
> KB> should let you get the information in a format you like.
> KB>
> KB> If you download the linked data files and you're interested in actual
> KB> headings (as opposed to traversing relationships), grep and sed in
> KB> combination with the join utility are handy for extracting the
> elements you
> KB> want and flattening the relationships into something more convenient
> to
> KB> work with. But there are plenty of other tools that you could also
> use.
> KB>
> KB> If you don't already have a convenient environment to work on, I'm a
> fan
> KB> of virtualbox. You can drag and drop things into and out of your
> regular
> KB> desktop or even access it directly. That way you can view/manipulate
> files
> KB> with the linux utilities without having to deal with a bunch of
> clunky file
> KB> transfer operations involving another machine. Very handy for when
> you have
> KB> to deal with multigigabyte files.
> KB>
> KB> kyle
> KB>
> KB> On Mon, Sep 29, 2014 at 11:19 AM, Jean Roth <[log in to unmask]> wrote:
> KB>
> KB> > Thank you! It looks like the files are available as RDF/XML,
> Turtle, or
> KB> > N-triples files.
> KB> >
> KB> > Any examples or suggestions for reading any of these formats?
> KB> >
> KB> > The MARC Countries file is small, 31-79 kb. I assume a script that
> KB> > would read a small file like that would at least be a start for the
> LCNAF
> KB> >
> KB> >
> KB>
#!/usr/bin/perl
####################################################################
#
# Michael Doran, University of Texas at Arlington
# [log in to unmask]
#
# @ OCLC Developer House
# February 3-7, 2014
#
# Proof-of-concept for extracting, parsing, and displaying
# a library's hours from institutional data in the
# OCLC WorldCat Registry.
# see: http://www.worldcat.org/registry/Institutions
#
# Requires non-core Perl module(s) and CA Root certs file
#
####################################################################
use strict;
####################################################################
# Configuration -- start
####################################################################
# OCLC organization number (not symbol) for main library unit
# aka "Institution Registry ID"
# examples:
# 2928 for University of Texas at Arlington Library
# 128807 for OCLC WorldShare Platform Sandbox Institution
#my $oclc_org_no = '2928';
my $oclc_org_no = '128807';
# Path to SSL Root Certificate Authority bundle file
# - required for HTTPS gets
my $cert_file = '../../ssl.crt/ca-bundle.crt';
# Labels for normal and special hours display
my $normal_hrs_label = 'REGULAR HOURS';
my $special_hrs_label = 'SPECIAL HOURS';
####################################################################
# Configuration -- end
####################################################################
# Required modules
use LWP::UserAgent;
use RDF::Helper;
#use Date::Calc; # Not used yet, but needed for further development
my $oclc_org_base_url = "https://www.worldcat.org/wcr/organization/resource/$oclc_org_no";
my $content = '';
my $normal_hours_uri = '';
my $normal_hours_rdf = '';
my $special_hours_uri = '';
my $special_hours_rdf = '';
my $null = undef;
my $ua = LWP::UserAgent->new;
$ua->timeout(10);
$ua->default_header('Accept' => 'application/rdf+xml');
$ua->ssl_opts( SSL_ca_file => "$cert_file" );
my $rdf = RDF::Helper->new(
BaseInterface => 'RDF::Trine',
namespaces => {
rdf => "http://www.w3.org/1999/02/22-rdf-syntax-ns#",
wcir => "http://purl.org/oclc/ontology/wcir/",
schema => "http://schema.org/",
rdfs => "http://www.w3.org/2000/01/rdf-schema#",
umbel => "http://umbel.org/umbel#",
foaf => "http://xmlns.com/foaf/0.1/",
library => "http://purl.org/library/",
xsi => "http://www.w3.org/2001/XMLSchema-instance",
dcterms => "http://purl.org/dc/terms/"
},
ExpandQNames => 1
);
GetInstData();
NormalHours($normal_hours_uri);
SpecialHours($special_hours_uri);
exit(0);
#########################
# GetRDFDoc
#########################
sub GetRDFDoc {
my ($uri) = @_;
my $response = $ua->get("$uri");
if ($response->is_success) {
$content = $response->decoded_content;
}
else {
die $response->status_line;
}
}
#########################
# GetInstData
#########################
sub GetInstData {
GetRDFDoc("$oclc_org_base_url");
$rdf->include_rdfxml(xml => $content);
my $hash_ref = $rdf->tied_property_hash($oclc_org_base_url);
my %prop_value_hash = %$hash_ref;
my $institution = $prop_value_hash{'wcir:institutionName'};
my $library = $prop_value_hash{'wcir:unitName'};
$normal_hours_uri = $prop_value_hash{'wcir:normalHours'};
$special_hours_uri = $prop_value_hash{'wcir:specialHours'};
print "\n" . "$institution" . "\n";
if ($library) {
print "$library" . "\n";
}
}
#########################
# NormalHours
#########################
sub NormalHours {
my ($normal_hours_uri) = @_;
unless ($normal_hours_uri) {
return;
}
print "\n" . "$normal_hrs_label" . "\n\n";
$normal_hours_rdf = GetRDFDoc("$normal_hours_uri");
$rdf->include_rdfxml(xml => $normal_hours_rdf);
my $norm_hours_hash_ref = $rdf->tied_property_hash($normal_hours_uri);
my %norm_value_hash = %$norm_hours_hash_ref;
foreach my $week_day ('Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday') {
my $day_hash_ref = $rdf->tied_property_hash("$normal_hours_uri#$week_day");
my %day_hash = %$day_hash_ref;
my $open_status = $day_hash{'wcir:openStatus'};
my $open_hour = $day_hash{'wcir:opens'};
my $close_hour = $day_hash{'wcir:closes'};
if ($open_status eq "Open24Hours") {
print "$week_day open 24 hours" . "\n";
} elsif ($open_status eq "Open") {
print "$week_day open from $open_hour to $close_hour" . "\n";
} elsif ($open_status eq "Closed") {
print "$week_day is closed" . "\n";
}
}
}
#########################
# SpecialHours
#########################
sub SpecialHours {
unless ($special_hours_uri) {
return;
}
print "\n" . "$special_hrs_label" . "\n";
$special_hours_rdf = GetRDFDoc ("$special_hours_uri");
$rdf->include_rdfxml(xml => $special_hours_rdf);
my $spec_hours_hash_ref = $rdf->tied_property_hash($special_hours_uri);
my %spec_value_hash = %$spec_hours_hash_ref;
# problem area here - fixed
# - when single value returned to $hoursSpecs, can't dereference
# - if don't deference, can't handle when it is an array reference returned,
# e.g. ARRAY(0x7fd4c2b34f40)
# Solution: test with perl 'ref' function
my $hoursSpecs = $spec_value_hash{'wcir:hoursSpecifiedBy'};
my @deref_hoursSpecs;
if (ref($hoursSpecs)) {
@deref_hoursSpecs = @$hoursSpecs;
} else {
@deref_hoursSpecs = $hoursSpecs;
}
my %spec_hours_instances;
foreach my $i (@deref_hoursSpecs) {
my $day_hash_ref = $rdf->tied_property_hash("$i");
my %day_hash = %$day_hash_ref;
my $valid_from = $day_hash{'wcir:validFrom'};
$spec_hours_instances{$valid_from} = $i;
}
foreach my $key (sort keys %spec_hours_instances) {
print "\n";
my $day_hash_ref = $rdf->tied_property_hash("$spec_hours_instances{$key}");
my %day_hash = %$day_hash_ref;
my $description = $day_hash{'wcir:description'};
my $open_status = $day_hash{'wcir:openStatus'};
my $open_hour = $day_hash{'wcir:opens'};
my $close_hour = $day_hash{'wcir:closes'};
my $valid_from = $day_hash{'wcir:validFrom'};
my $valid_to = $day_hash{'wcir:validTo'};
print "$description" . "\n";
if ($open_status eq "Open24Hours") {
print "Open 24 hours" . "\n";
} elsif ($open_status eq "Open") {
print "Open from $open_hour to $close_hour" . "\n";
} elsif ($open_status eq "Closed") {
print "Closed" . "\n";
}
print "From $valid_from to $valid_to" . "\n";
}
}
|













{kind=link}
{kind=link}