Stuart,
Since triplestores, in essence, store graph data I think a slightly better question is what can you do with graph data (if you do not mind me rephrasing you question).
From this perspective I would point to Facebook or LinkedIn as prime examples of what can be done with graph data. Obviously those do not necessarily translate well into what can be done with library graph data but it does show the potential. For libraries, I think one of the benefits will be expanded/enhanced discoverability for resources.
With graph data it is much easier to search for an author (lets say Jane Austen) and find not only all of the books that she authored but also all of the books about her, all of the books that are about similar topics, published in similar periods. One can then imaging hopping from the Jane Austen node on the graph to a node that is a book she wrote (say Pride and Prejudice) and then to a subject node for the book (say "Social Classes--Fiction). From there you could then find all of the Authors that wrote books about that same topic and then navigate to those books.
Our current ILS systems try t o do this with MARC records but because they are mostly string based, it is very difficult to accurately provide this type of information to users. Graph data helps overcome this hurdle.
This was a rather basic example of how end-users can benefit from graph data but I think it is a compelling reason.
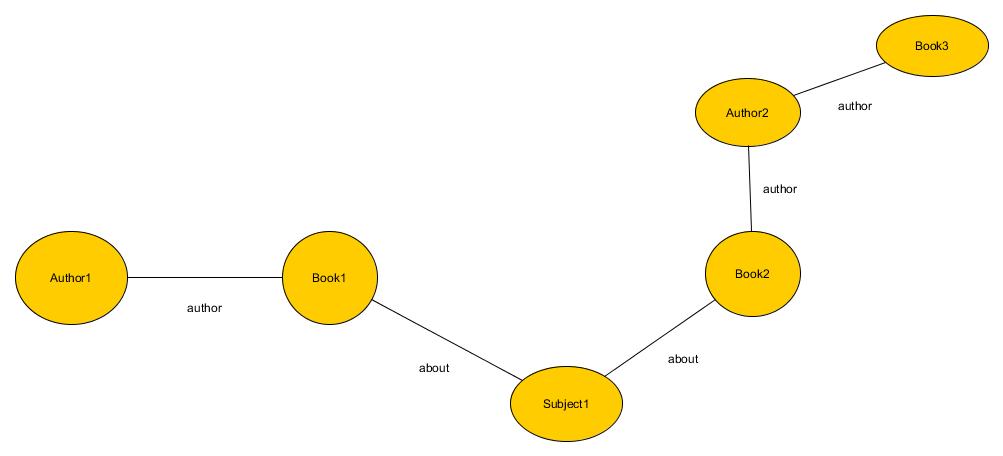
I have attached a simple image to help visualize what I was talking about. In it the user would start by finding Author1 and then using the graph we (the library) could suggest that they might like Book2 (since it is about the same subject) or even Book3 (since it is by Author2 who wrote a book, Book2, that shared a common subject, Subject1, with the author, Author1, that was originally searched for. Again, this is very basic but would be rather difficult to do with a string base record system.
If you wanted to add complexity, you could start talking about discover of multi-lingual items for bilingual users (since graph data should be language neutral).
Thanks,
Jeff Mixter
Research Support Specialist
OCLC Research
614-761-5159
[log in to unmask]
________________________________________
From: Code for Libraries <[log in to unmask]> on behalf of Forrest, Stuart <[log in to unmask]>
Sent: Friday, December 19, 2014 10:32 AM
To: [log in to unmask]
Subject: Re: [CODE4LIB] rdf triplestores
Thanks Jeff
Interesting concept, can you give me any examples of their usage, what kinds of data etc.?
Thanks
================================================================================
Stuart Forrest PhD
Library Systems Specialist
Beaufort County Library
843 255 6450
[log in to unmask]
http://www.beaufortcountylibrary.org
For Leisure, For Learning, For Life
-----Original Message-----
From: Code for Libraries [mailto:[log in to unmask]] On Behalf Of Mixter,Jeff
Sent: Friday, December 19, 2014 10:20 AM
To: [log in to unmask]
Subject: Re: [CODE4LIB] rdf triplestores
A triplestore is basically a database backend for RDF triples. The major benefit is that it allows for SPARQL querying. You could imagine a triplestore as being the same thing as a relational database that can be queried with SQL.
The drawback that I have run into is that unless you have unlimited hardware, triplestores can run into scaling problems (when you are looking at hundreds of millions or billions of triples). This is a problem when you want to search for data. For searching I use a hybrid Elasticsearch (i.e. Lucene) index for the string literals and the go out to the triplestore to query for the data.
If you are looking to use a triplestore it is important to distinguish between search and query.
Triplestore are really good for query but not so good for search. The basic problem with search is that is it mostly string based and this requires a regular expression query in SPARQL which is expensive from a hardware perspective.
There are a few triple stores that use a hybrid model. In particular Jena Fuseki (http://jena.apache.org/documentation/query/text-query.html)
Thanks,
Jeff Mixter
Research Support Specialist
OCLC Research
614-761-5159
[log in to unmask]
________________________________________
From: Code for Libraries <[log in to unmask]> on behalf of Forrest, Stuart <[log in to unmask]>
Sent: Friday, December 19, 2014 10:00 AM
To: [log in to unmask]
Subject: Re: [CODE4LIB] rdf triplestores
Hi All
My question is what do you guys use triplestores for?
Thanks
Stuart
================================================================================
Stuart Forrest PhD
Library Systems Specialist
Beaufort County Library
843 255 6450
[log in to unmask]
http://www.beaufortcountylibrary.org
For Leisure, For Learning, For Life
-----Original Message-----
From: Code for Libraries [mailto:[log in to unmask]] On Behalf Of Stefano Bargioni
Sent: Monday, November 11, 2013 8:53 AM
To: [log in to unmask]
Subject: Re: [CODE4LIB] rdf triplestores
My +1 for Joseki.
sb
On 11/nov/2013, at 06.12, Eric Lease Morgan wrote:
> What is your favorite RDF triplestore?
>
> I am able to convert numerous library-related metadata formats into RDF/XML. In a minimal way, I can then contribute to the Semantic Web by simply putting the resulting files on an HTTP file system. But if I were to import my RDF/XML into a triplestore, then I could do a lot more. Jena seems like a good option. So does Openlink Virtuoso.
>
> What experience do y'all have with these tools, and do you know how to import RDF/XML into them?
>
> --
> Eric Lease Morgan
>
|













{kind=link}