> On Feb 11, 2015, at 9:32 AM, Eric Lease Morgan <[log in to unmask]> wrote:
>
> On Feb 10, 2015, at 11:46 AM, Erik Hatcher <[log in to unmask]> wrote:
>
>> bin/post -c collection_name /path/to/file.doc
>
> The almost trivial command to index a Word document in Solr, above, is most certainly appealing, but I’m wondering about the underlying index’s schema.
>
> Tika makes every effort to extract as much metadata from Word documents as possible. This metadata includes dates, titles, authors, names of applications, last edit, etc. Some of this data can be very useful. The metadata can be packaged up as an XML file/stream and then sent to Solr for indexing. "Tastes great. Less filling.” But my question is, “To what degree does Solr know what to do with the metadata when the (kewl) command, above, is seemingly so generic? Does one need to create a Solr schema to specifically accommodate the Tika-created metadata, or do such things also come for ‘free’?”
Great questions. For the Solr 5 example I gave, here’s the fuller scoop:
First, let’s create a collection (or “core” in my single node environment):
$ bin/solr create -c c4l-example
By default, Solr 5 uses what is called the data driven schema. It’s set up to guess field types and add fields that it does not already have defined, so everything comes in automagically, mostly as strings unless something looks like a number.
Now post a Word doc since that’s what you were asking about specifically, Solr has one in it’s test files:
$ bin/post -c c4l-example ~/dev/lucene_solr_5_0/solr/contrib/extraction/src/test-files/extraction/word2003.doc
Now see what got indexed/stored:
$ curl "http://localhost:8983/solr/c4l-example/select?q=*:*&wt=json&indent=on"
{
"responseHeader":{
"status":0,
"QTime":0,
"params":{
"q":"*:*",
"indent":"on",
"wt":"json"}},
"response":{"numFound":1,"start":0,"docs":[
{
"id":"/Users/erikhatcher/dev/lucene_solr_5_0/solr/contrib/extraction/src/test-files/extraction/word2003.doc",
"cp_revision":[3],
"date":["2012-08-31T08:20:00Z"],
"company":["MARUM"],
"stream_content_type":["application/msword"],
"meta_word_count":[11],
"dc_creator":["Uwe Schindler"],
"extended_properties_company":["MARUM"],
"word_count":[11],
"dcterms_created":["2012-08-31T08:04:00Z"],
"dcterms_modified":["2012-08-31T08:20:00Z"],
"last_modified":["2012-08-31T08:20:00Z"],
"title":["Word 2003 Title"],
"last_save_date":["2012-08-31T08:20:00Z"],
"meta_character_count":[74],
"template":["Normal.dotm"],
"meta_save_date":["2012-08-31T08:20:00Z"],
"dc_title":["Word 2003 Title"],
"application_name":["Microsoft Office Word"],
"modified":["2012-08-31T08:20:00Z"],
"content_type":["application/msword"],
"stream_size":[22528],
"x_parsed_by":["org.apache.tika.parser.DefaultParser",
"org.apache.tika.parser.microsoft.OfficeParser"],
"creator":["Uwe Schindler"],
"meta_author":["Uwe Schindler"],
"extended_properties_application":["Microsoft Office Word"],
"meta_creation_date":["2012-08-31T08:04:00Z"],
"meta_last_author":["Uwe Schindler"],
"creation_date":["2012-08-31T08:04:00Z"],
"xmptpg_npages":[1],
"resourcename":["/Users/erikhatcher/dev/lucene_solr_5_0/solr/contrib/extraction/src/test-files/extraction/word2003.doc"],
"last_author":["Uwe Schindler"],
"character_count":[74],
"page_count":[1],
"revision_number":[3],
"extended_properties_template":["Normal.dotm"],
"author":["Uwe Schindler"],
"meta_page_count":[1],
"_version_":1492827810459287552}]
}}
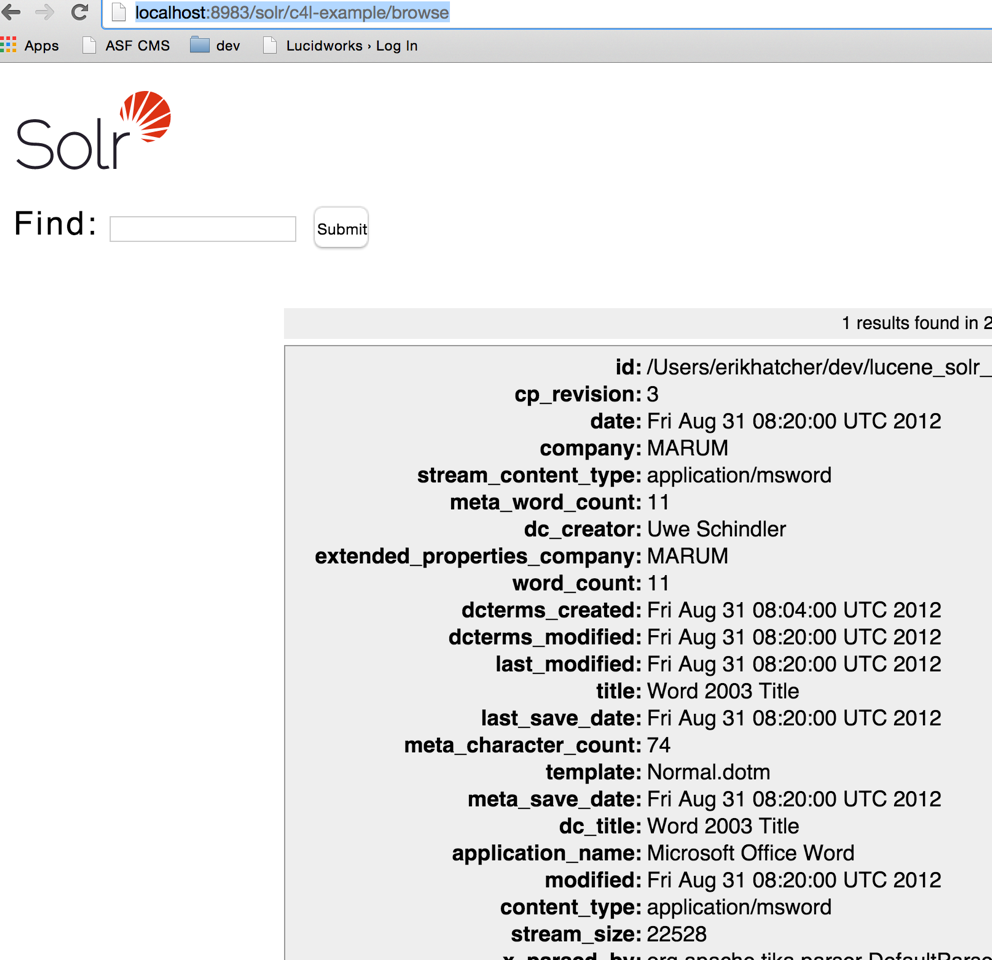
I attached a screenshot of going to http://localhost:8983/solr/c4l-example/browse out of the box. /browse is generically and cleanly wired in to the data driven config too :) (free of the techproducts example cruft that accumulated in 4x)
The data driven environment has the Solr Cell / Tika integration wired in like this:
<requestHandler name="/update/extract” startup=“lazy" class="solr.extraction.ExtractingRequestHandler" >
<lst name="defaults”>
<str name="lowernames">true</str>
<str name="fmap.meta">ignored_</str>
<str name="fmap.content">_text</str>
</lst>
</requestHandler>
The docs here cover the parameters and configuration details pretty well: <https://cwiki.apache.org/confluence/display/solr/Uploading+Data+with+Solr+Cell+using+Apache+Tika>
Using Solr 4’s default/example is slightly different on the field mapping stuff since it doesn’t have the field guessing/creating mojo and ignores (by mapping to ignored_*) unknown fields, but it does have some of these metadata fields that get extracted from Tika concretely defined in it’s schema.
*** Note, that you could also crawl a directory of files using `bin/post -c collection_name /path/to/dir/of/files
Hope all this helps.
Erik
p.s. and while I’ve got the podium, I’d be remiss to the paycheck provider not to mention that all of this rich text indexing/handling stuff is point and click easy with our Lucidworks Fusion platform - http://lucidworks.com/product/fusion/ - it’s got an indexing pipeline that can be (java)scripted to do whatever you want with all this metadata stuff in the pipeline UI. There’s query pipelines in there too. Crawl a file system, rip out metadata (or do something fancy with the full text to categorize or whatever), and rock on!
|













{kind=link}