On May 7, 2019, at 11:59 AM, Junior Tidal <[log in to unmask]> wrote:
> The newest issue of code4Lib Journal is now available - https://journal.code4lib.org/issues/issues/issue44
For a good time, I fed all of the articles from the current Code4Lib Journal to my application/system called the Distant Reader. [1] The Reader outputs somewhat interesting results. For example, here is the list of alphabetic keywords:
app; apps; archival; archives; archivesspace; audio; book;
books; collection; collections; data; date; dates; develop;
developed; developer; developers; developing; development;
digital; digitization; digitized; display; displaying;
displays; editor; editors; email; emailing; emails;
equipment; field; fields; http; https; libraries; library;
mobile; mobiles; mobilization; mobilizing; new; news;
problem; problems; project; projects; record; recorded;
recorder; recording; recordings; records; repositories;
repository; search; searches; searching; software; space;
spaces; studies; studio; study; technical; tei; title;
titles; user; users; video; videos; widget; widgets
Not too surprising.
Here is a list of automatically generated textual summaries:
* by Raffaele Viglianti, Marcus Emmanuel Barnes, Natkeeran
Ledchumykanthan, Kirsta Stapelfeldt Introduction Early Modern
Songscapes (EMS) is an interdisciplinary web project co-developed
by the University of Toronto Scarborough’s Digital Scholarship
Unit (DSU), the University of Maryland (including the Maryland
Institute for technology in the Humanities), and the University
of South Carolina.
* Building on a method created by the Orbis Cascade Alliance, we
built a Google form that allows users to report problems
connecting to full text (or any other issue) and automatically
includes the permalink in their response. We soon realized that
we could improve the user experience by automatically forwarding
these reports into our Ask a Librarian email service (LibAnswers)
so we could offer alternative solutions while we worked on fixing
the initial issue.
* Without a practical solution for an academic library, East
Tennessee State University developed an automated process to
generate book widgets utilizing data from Alma Analytics. Our
efforts of creating a book slider for each subject guide relied
on separate Alma analytics reports and scripts for automation. In
order to reduce the amount of repeat cURL calls every time the
import process occurs, we started storing the cover image URL,
current date, and the corresponding MMS_ID (Alma record ID) in a
separate array file.
* In the case of this study, search logs were analyzed to
understand the popularity of mobile device types used (e.g., iOS
and Android devices), the nature of search terms in mobile
searches (the number of words per query), and VuFind search
facets used and not used in mobile search of the library catalog.
Logs of both native and responsive mobile apps can be compared
for search terms used, search query length, and relative
popularity of each access type across the state, e.g., baseline
data about the use of each.
* We began discussing what services we would actually need to
support search, display, and data backup and integrity in a more
distributed ecosystem, and began seriously considering a solution
based on the microservices architectural model, where multiple
single-purpose systems are integrated to provide the
functionality of a larger piece of multi-purpose software. Our
digital collections and preservation librarian explored and
implemented FITS in her file characterization workflows to enable
us to generate and store technical metadata.
* The primary focus of this equipment request was to: Obtain
equipment necessary to utilize Penn State’s One Button Studio
software Allow for the use of a teleprompter Slim down the
lighting set-up with compact LED light panels Provide some sound
proofing of the space with sound treatment foam Bolster the audio
recording capabilities with a mix board Add a backdrop to make
video recordings more professional and visually appealing Table
4.
* When authors contribute to the journal, they are given an
optional demographic survey that collects information including
ethnicity/cultural identity, gender, location (country),
disability, and institution type. Data that has been disclosed
indicates that a majority of authors (52%) identify as white (see
figure 1), with the second most largest group that responded to
the survey indicated “no response.” Contributors’ self-reported
gender identities show that this has slightly changed.
* We first heard of the Timewalk date parsing plugin for
ArchivesSpace from discussions with fellow members of the user
community, and we considered ways we could use the plugin to work
with legacy data.[8] We knew that the parsing function was
triggered upon saving a record in the ArchivesSpace staff
interface, so we attempted, in a test instance, to GET/POST a
number of records via the API without making any changes.
What is discussed in the issue can be enumerated by looking at the lemmatized nouns:
alma; app; archivesspace; article; book; collection; datum;
device; display; equipment; experience; field; figure; format;
information; interface; library; log; microphone; primo; problem;
process; project; record; report; result; script; search;
service; software; solution; source; space; staff; studio; study;
system; tei; text; time; title; type; university; use; user;
video; web; widget; work
The actions in articles are enumerated by the verbs:
add; allow; analyze; base; be; begin; build; call; choose; come;
consider; contain; create; develop; do; exist; find; follow;
generate; get; have; help; identify; implement; improve; include;
look; make; need; offer; present; provide; publish; receive;
record; report; require; run; see; set; show; store; support;
take; understand; use; want; work; write
Things and actions in the articles are described with adjectives:
able; academic; additional; audio; available; creative; current;
dedicated; different; digital; early; easy; electronic; few;
first; free; full; future; general; good; great; initial; large;
many; mobile; more; most; multiple; native; new; next; old; open;
other; own; possible; primary; repository; responsive; same;
several; similar; single; specific; subject; such; technical;
top; useful
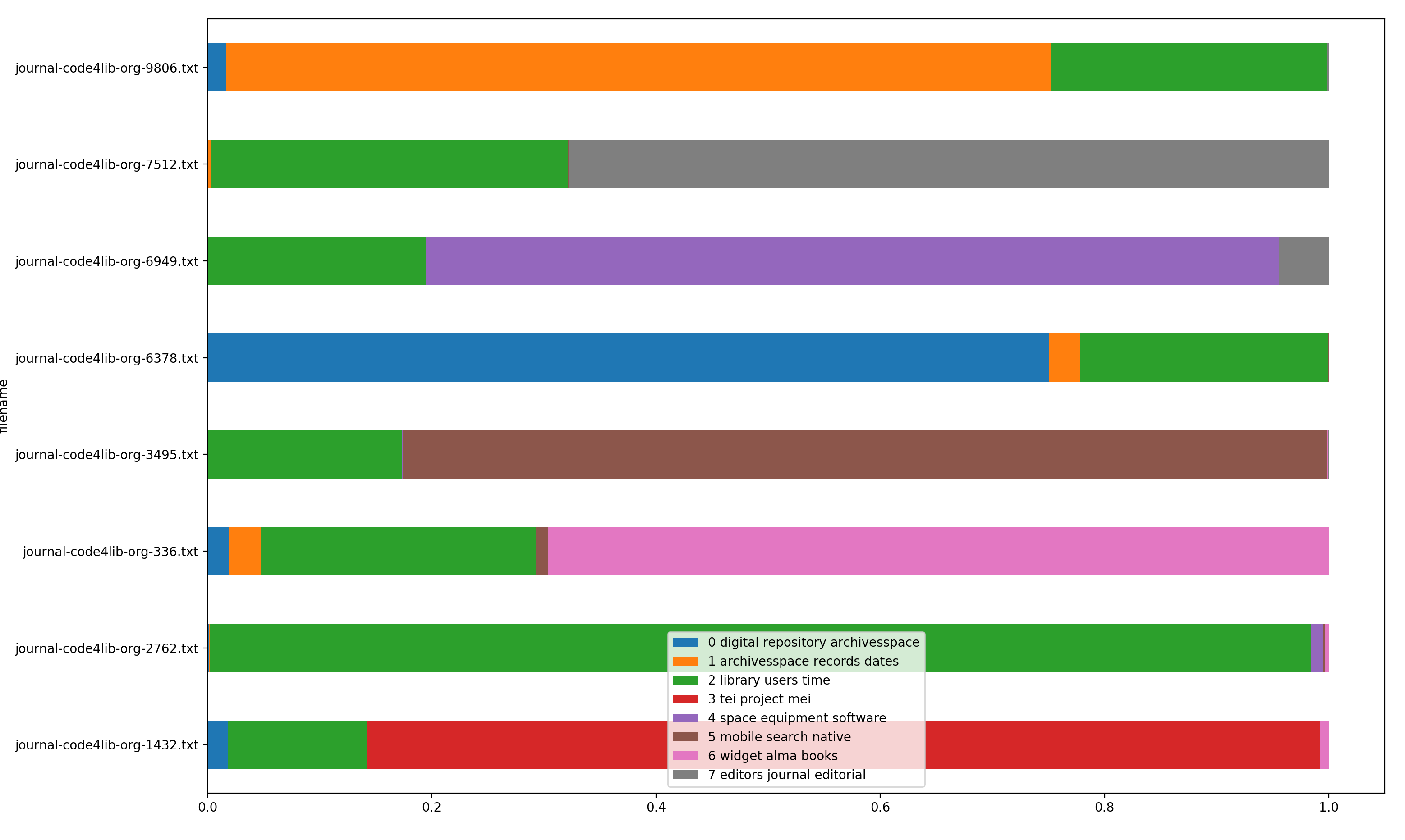
When I topic model on the issue and request a single word with a single dimension, then the resulting word is "library". Duh! Since there were eight articles, I topic modeled on eight topics with three dimensions, and this is what I got:
* digital collections repository
* archivesspace records dates
* library users time
* tei project mei
* space equipment software
* mobile search native
* widget alma books
* editors journal data
I then visualized the topics in the attached image, and you can observe two things:
1. each article discusses a single topic; each article is dominated by a single color
2. the topic of "library users times" (the green topic) is mentioned by each article
The Distant Reader is functional, but not necessarily usable. It does not crash nor does it output bogus data. I can feed the Reader a single URL, such as the root of Planet Code4Lib, and it will then consume the whole thing (hundreds and hundreds of URLs) summarizing the results. I can query a local, full text index of Project Gutenberg, find all the writings of Longfellow, Emerson, Melville, or Thoreau, generate a list of URLs pointing to the found items, feed them to the Reader, and consume them too. [3]
Again, the Distant Reader is functional but not necessarily usable. It creates a "study carrel" in the form of a .zip file, as well as a summary file. [4, 5] The study carrel includes bunches o' other files which can be analyzed in OpenRefine, queried through SQL, topic modeled, read "closely" because the original documents are included in the archive, etc. Learning how to use the "study carrel" can be a challenge, and a few things are in the pipeline: writing documentation, enhancing the job submitting process, writing a Web interface to query the study carrel, and including tools in the study carrel for using it accordingly.
Finally, for the sysops and application programmers in the room, The Distant Reader employs high performance computing techniques. Jobs are submitted to a head node, virtual machines are spun up, the jobs are executed, the machines are spun down, and the output is made available. Each virtual machine has 10 CPUs, plenty of RAM, and more disk space than I can use. The whole thing is embarrassingly parallel, and my cores are almost always max'ed out. In total, the system has 144 cores at my disposal, and it is all sponsored by the good people at XSEDE.†
Fun with HPC to do NLP.
[Eric goes off to "read" the whole of a newspaper called the Catholic Worker. [6]]
† This work used the Extreme Science and Engineering Discovery Environment (XSEDE), which is supported by National Science Foundation grant number ACI-1548562. Development of the Apache Airavata used to develop the science gateway is supported by NSF award #1339774. XSEDE resources used include JetStream and ECSS support.
[1] The Distant Reader - https://distantreader.org/pages/about
[2] Planet Code4Lib - https://planet.code4lib.org
[3] Longfellow, Emerson, Melville, or Thoreau - https://ntrda.me/2H3RsE0
[4] Code4Lib Issue #44 "study carrel" - http://dh.crc.nd.edu/tmp/code4lib-issue44.zip
[5] Code4Lib Issue #44 summary - http://dh.crc.nd.edu/tmp/code4lib-issue44.txt
[6] Catholic Worker - http://bit.ly/2VnSjsY
--
Eric Lease Morgan
University of Notre Dame
|













{kind=link}