On May 24, 2019, at 9:28 PM, Jodi Schneider <[log in to unmask]> wrote:
> EBSCO gets index data from the Code4Lib Journal. I'm cc-ing the editorial
> board in the hopes that somebody will be able to tell you how to get ahold
> of the metadata.
Jodi, thanks, and I will wait patiently.
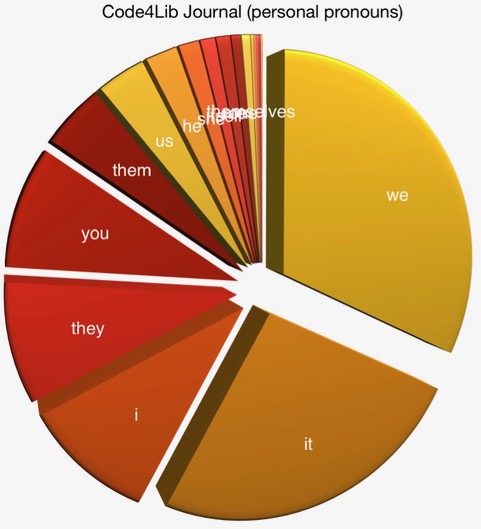
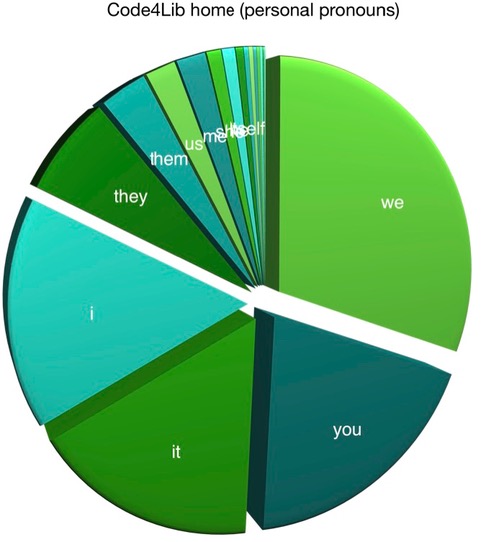
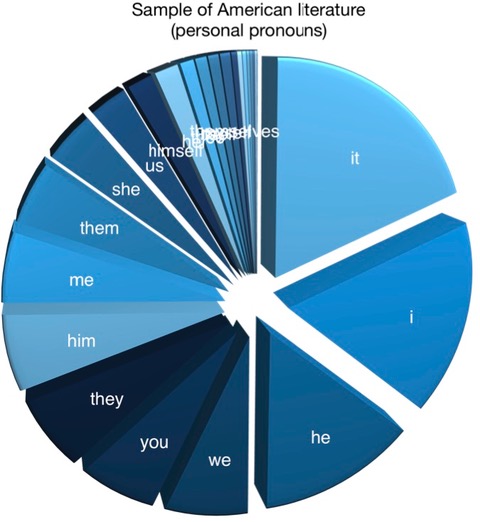
For a good time, I indexed the whole of the Code4Lib journal and then I did a bit of "reading" for personal pronouns. What I saw there was a language of inclusivity. Here how I did it:
1. Created a list of all journal articles [1]
2. Harvested/cached them locally [2]
3. Converted them into plain text [3]
4. Analyzed each article for parts-of-speech [4]
5. Reduced the whole to a database
6. Queried the database for features (tokens) denoted as personal pronouns and grouped the result [5]
7. Charted the result [6]
I then repeated the process against both the Code4Lib home page (and its immediate links) as well as a sample of 85 texts from traditional American literature. The Code4Lib pages (both the home pages as well as the journal) exhibit pronouns such as "we", "you", "it", and "I". Whereas the pronouns from the American literature are much more gender-ized as well as self-centered with pronouns such as "it", "I", and "he".
Through the exploitation of natural language processing, the indexing of things like Code4Lib Journal can be much richer.
[1] list of journal articles - http://dh.crc.nd.edu/tmp/code4lib-journal/input-file.txt
[2] cache - http://dh.crc.nd.edu/tmp/code4lib-journal/cache/
[3] plain text - http://dh.crc.nd.edu/tmp/code4lib-journal/txt/
[4] parts-of-speech - http://dh.crc.nd.edu/tmp/code4lib-journal/pos/
[5] query - SELECT COUNT( LOWER( token ) ) AS c, LOWER( token ) FROM pos WHERE pos IS 'PRP' GROUP BY LOWER( token ) ORDER BY c DESC
[6] result - http://dh.crc.nd.edu/tmp/code4lib-journal/code4lib-journal.xlsx
--
Eric Morgan
University of Notre Dame
|













{kind=link}
{kind=link}
{kind=link}