Why are there so many kernel threads in my processing?
I have a Bash script, attached. At its core it:
* reads each line of the input file (sans the first one)
* parses the line into fields
* escapes single quote characters in a few fields
* builds an SQL INSERT statement
* appends the statement to a variable
* when done with all lines, the variable is output as a file
This process seems too slow, and I can't figure out why. Granted, some of the input files may be megabytes in size, and some of my input files have more fields than others.
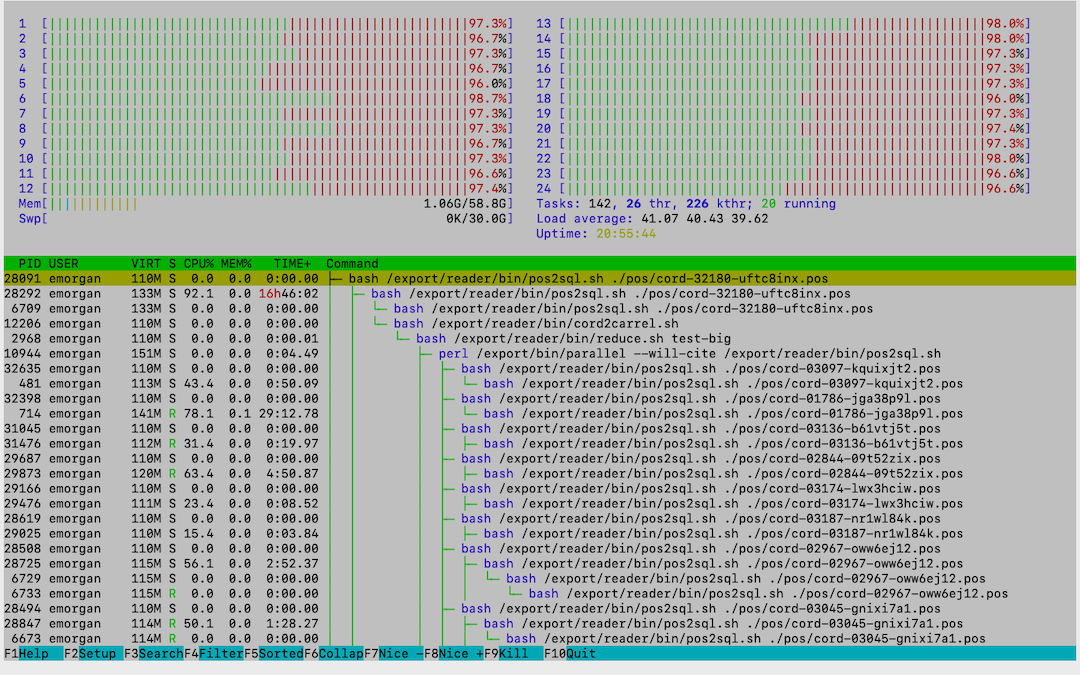
When I use htop to observe what is going on, I see half the processing is red (kernel processes).
Can you give me some advice as to why things are so slow? Is cat too big? Is tail too big? Is the parsing labor intensive? Do I have too many piped processes? Is sed inherently slow?
Attached is a a screen dump illustrating the state of the processors.
Any help would be appreciated. How can I increase the thru-put of my script?
--
Eric Morgan
University of Notre Dame
#!/usr/bin/env bash
# pos2sql.sh - given a TSV file of keywords, output a set of SQL INSERT statements
# usage: mkdir -p ./tmp/sql-pos; find ./pos -name "*.pos" | sort | parallel --will-cite /export/reader/bin/pos2sql.sh
# Eric Lease Morgan <[log in to unmask]>
# (c) University of Notre Dame and distributed under a GNU Public License
# June 21, 2020 - based on other work
# configure
SQLPOS='./tmp/sql-pos'
TEMPLATE="INSERT INTO pos ( 'id', 'sid', 'tid', 'token', 'lemma', 'pos' ) VALUES ( '##ID##', '##SID##', '##TID##', '##TOKEN##', '##LEMMA##', '##POS##' );"
if [[ -z $1 ]]; then
echo "Usage: $0 <pos>" >&2
exit
fi
# initialize
TSV=$1
BASENAME=$( basename $TSV .pos )
IFS=$'\t'
# debug
echo "$BASENAME" >&2
# if the desired output already exists, then don't do it again
if [[ -f "$SQLPOS/$BASENAME.sql" ]]; then exit; fi
# extract document_id; I wish they had given me a key
DOCUMENTID=$( echo $BASENAME | cut -d'-' -f2 | sed 's/^0*//' )
# configure and then process each line in the file, sans the header
cat $TSV | tail -n +2 | ( while read ID SID TID TOKEN LEMMA POS; do
# escape
TOKEN=$( echo $TOKEN | sed "s/'/''/g" )
LEMMA=$( echo $LEMMA | sed "s/'/''/g" )
# create an INSERT statement and then update the SQL
INSERT=$( echo $TEMPLATE | sed "s/##ID##/$DOCUMENTID/" | sed "s|##SID##|$SID|" | sed "s|##TID##|$TID|" | sed "s|##TOKEN##|$TOKEN|" | sed "s|##LEMMA##|$LEMMA|" | sed "s|##POS##|$POS|" )
SQL="$SQL$INSERT\n"
done
# output
echo -e "$SQL" > "$SQLPOS/$BASENAME.sql"
)
# done
exit
|













{kind=link}