We have a lightweight ‘intranet~ish’ utility running to try and handle this. It doesn’t get a whole lot of use in practice even though it’s been advertised around the library but for those of us who do use it, it’s generally helpful and easy to maintain.
Essentially we have 1 page Jekyll site that pulls a list of links/resources from its data directory where each item is an entry in one of a couple of YAML files. The site lives in a git repo and is built and then deployed locally via a gitlab instance, accessible only in the buildings or over VPN.
All the fields in the YAML file are of course arbitrary to us, but we maintain (loosely) a list of systems/links, important Filesystem directories, names of committees/workgroups etc.
Our main site happens to also be built in Jekyll and we have our staff directories and organizational chart as collection items there, and those collections are stored as independent git repositories from the main site, and so we use submodules to pull the relevant metadata about people/depts into both the main site and the intranet as well. Everything gets printed to a big list and there is an autocomplete search/filter in sidebar powered by list.js that will reduce the visual list down to the thing the person is looking for on input.
Finally there are a couple of small utility links baked into the template that will jump folks out into MS office suite tools, their one drive account (they set it with an input field and it’s stored in localstorage), and there’s a link into the gitlab issue tracker for someone to request a new or updates to items (no one ever does).
This was built pre-MS teams which has stolen a lot of the intranet storage problems for most folks in our org but to some extent further exasperated the problem. And although we could do so, we don’t store any files in this thing. Think of it mostly as a sort of a dumbed down single-author del.icio.us.
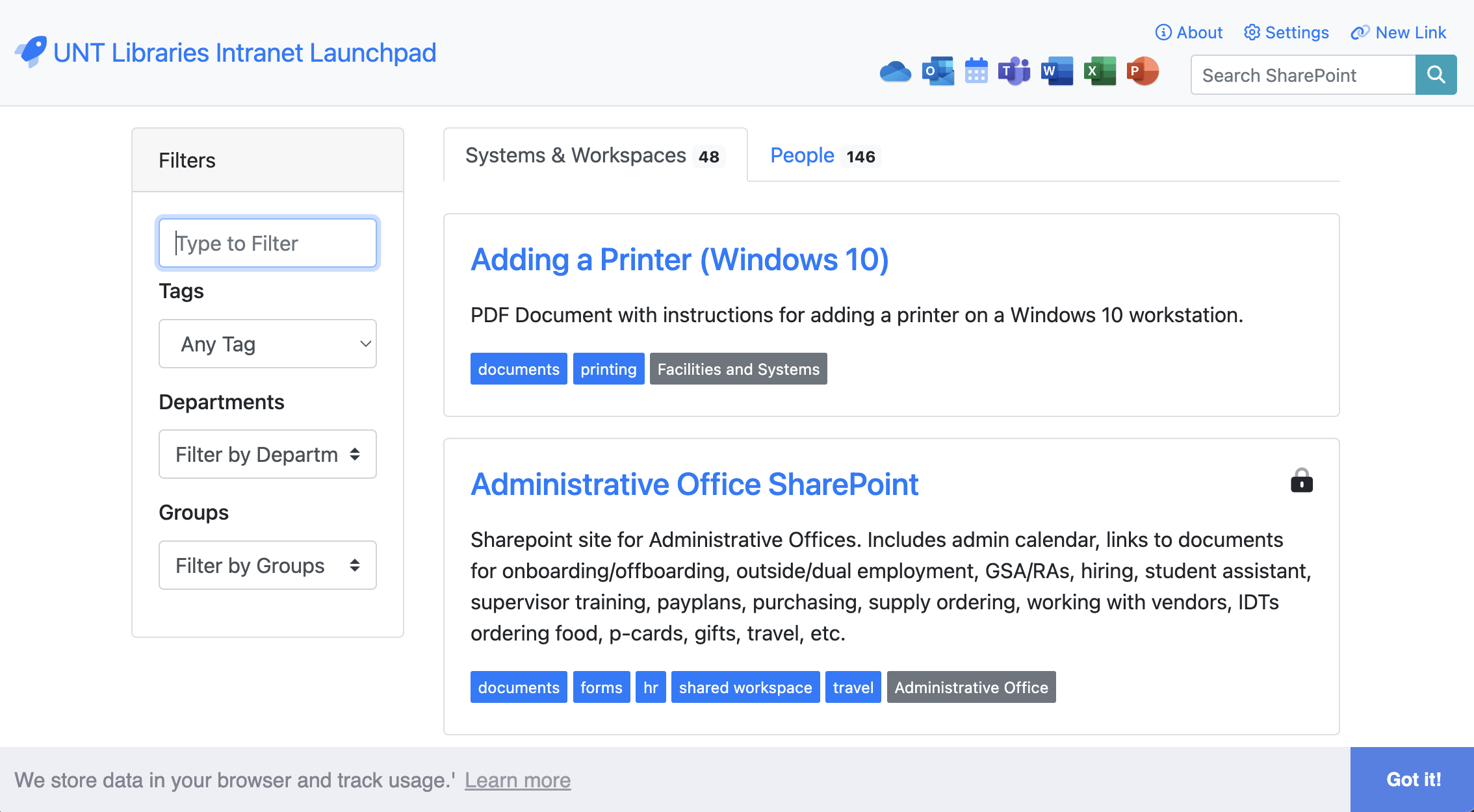
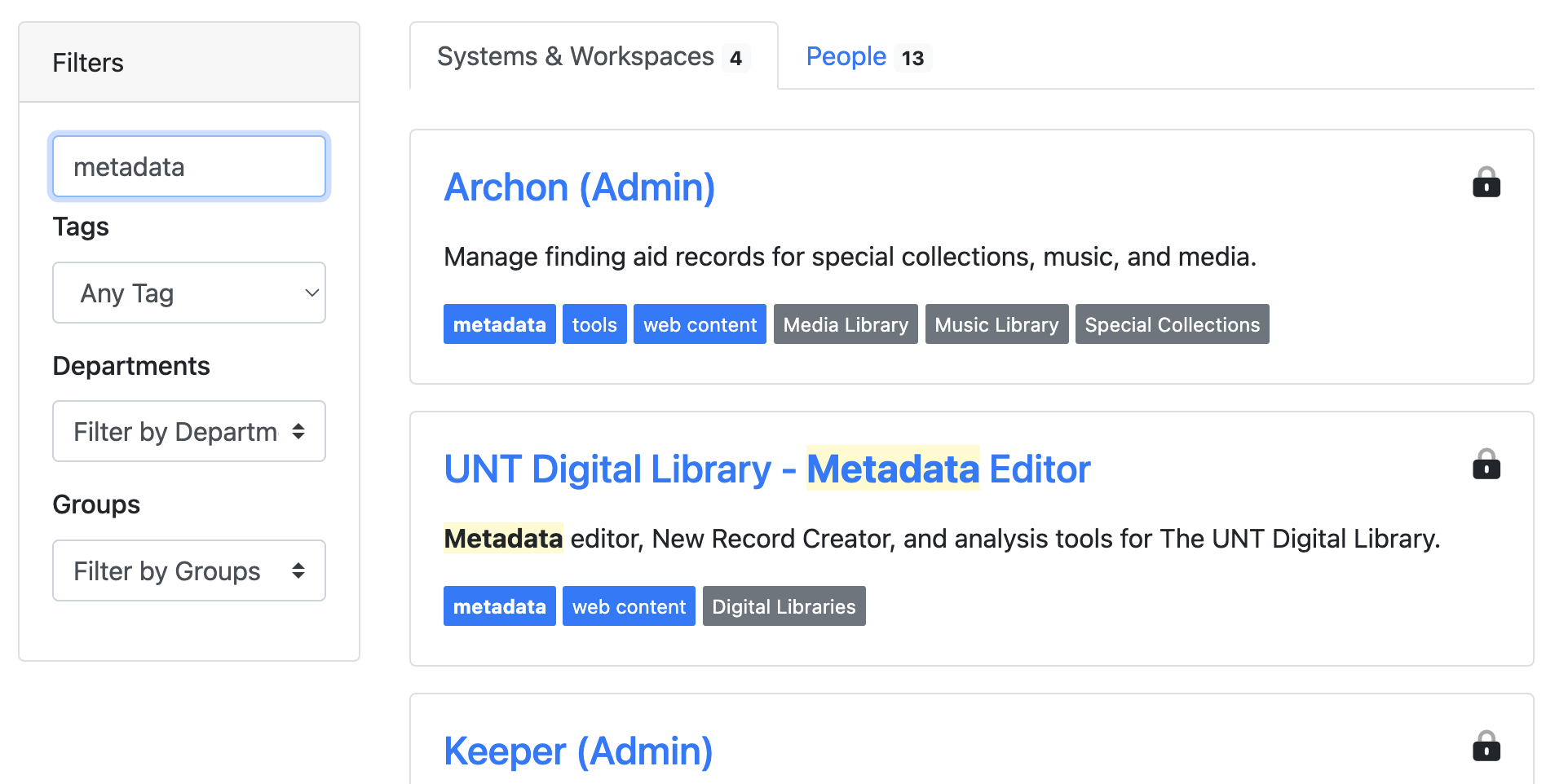
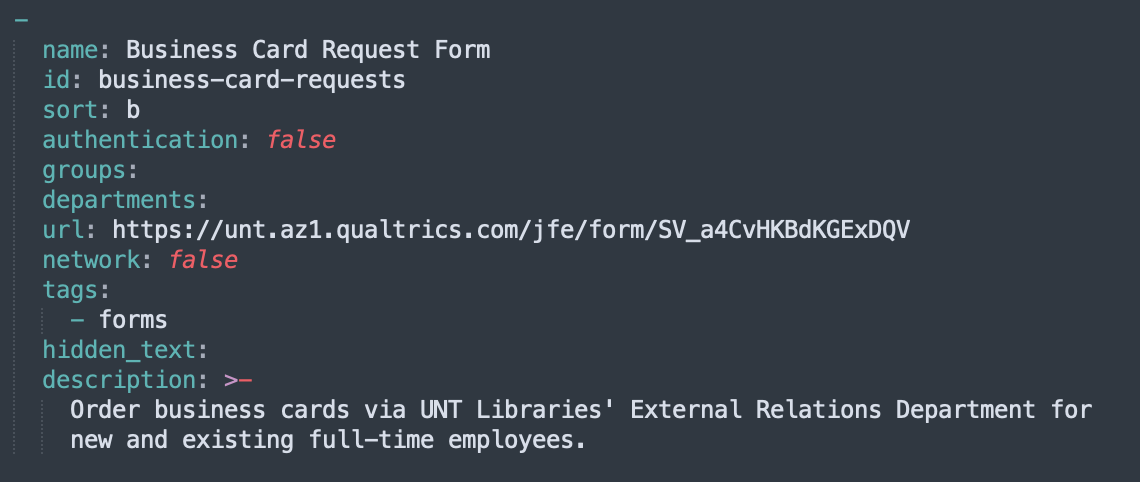
Screenshots:
[A screenshot of a computer Description automatically generated]
[A screenshot of a computer Description automatically generated]
[A screenshot of a computer Description automatically generated]
Cheers,
W
From: Code for Libraries <[log in to unmask]> on behalf of Margaret Alexander <[log in to unmask]>
Date: Tuesday, November 28, 2023 at 11:15 AM
To: [log in to unmask] <[log in to unmask]>
Subject: [EXT] Re: [CODE4LIB] How does your library manage internal utilities metadata?
[Some people who received this message don't often get email from [log in to unmask] Learn why this is important at https://aka.ms/LearnAboutSenderIdentification ]
I completely agree. One of our developers took another job 4 years ago, and we are still finding little apps and dependencies that we know nothing about but are still in use. Not to mention the ones that are NOT still in use, but are still squirreled away on servers, and we have to figure out who might have been using them to decide if they need to be migrated when the server is upgraded, etc.
Which is to say, I don't have a solution, but am determined to get our knowledge documented, and I'd love to hear what others are doing, too.
Best,
Margaret Alexander
Core Systems Librarian
University of Oregon Libraries
-----Original Message-----
From: Code for Libraries <[log in to unmask]> On Behalf Of Hammer, Erich F
Sent: Tuesday, November 28, 2023 8:14 AM
To: [log in to unmask]
Subject: [CODE4LIB] How does your library manage internal utilities metadata?
Between administrative interfaces for internal and third-party Library service applications, IT/networking services, support services, etc., I have around 3 dozen bookmarks just to (barely) manage my responsibilities. That doesn't include the various forms for requesting other people do other things with their tools/utilities. The other departments like Access Services, Reference, Archives, Purchasing, HR etc. have their own utilities and services for their needs, and I've been wondering if anyone is actually keeping track of all of these internal needs in case someone else suddenly needs to take over any particular job. Because of reduced staffing, there is almost no redundancy, thus, I know unquestionably that should I get hit by the Lotto bus, there are lesser-used-but-still-vital systems/services that nobody else knows how to access. They might know of them and are probably smart enough to figure out at least some basics if plopped in front of them, but how to get to them has limited/no documentation.
I've been thinking that our fundamental function is keeping track of information, so shouldn't the Library also *collectively* keep track of all the tools/utilities necessary to keep the library functioning? I imagine that just a giant list would be too overwhelming when an individual employee might only need a small percentage of them, so some means of indexing/searching is probably required. Does anyone here do have a shared/collective solution, or does each department (or worse, individual) just keep that information separately and internally? Do you use a third-party product (what?), or have you constructed your own solution? Do you keep track of shared credentials or the individual staff members who hold credentials?
Thanks,
Erich
--
Erich Hammer Head of Library Systems
[log in to unmask] University Libraries
518-442-3891 University @ Albany
The perversity of the Universe tends towards a maximum.
|













{kind=link}
{kind=link}
{kind=link}